

产品中心
新闻资讯
,这是一个免训练的流式系统,专为视频扩散模型设计,用于实现动态交互式的视频生成。
巧妙整合了SLO-aware批处理调度器、块调度器、sink-token引导的滚动KV缓存以及运动感知噪声控制器等创新组件,同时引入可扩展的pipeline编排机制。
该系统首次在多GPU环境下实现了实时SLO约束下的高效生成,支持从单个创作者到企业级平台的广泛应用场景。显著提升了视频生成的时效性和质量稳定性,推动了AI驱动的直播流媒体向下一代发展。

图 1 批量视频生成与流式视频生成的比较。与生成大批量视频不同,实时流视频生成的目标是缩短 到第一帧的时间,并以较低的延迟生成连续输出
现有视频扩散模型虽在离线生成中表现出色,但难以适应实时直播流媒体的严格要求。具体而言,有以下四大挑战:
这些问题源于现有系统对离线批处理优化的偏向,而忽略了在线流媒体的无限输入和低抖动需求。本工作通过系统级优化,填补了这一空白。
StreamDiffusionV2,这是一个端到端的免训练pipeline,将高效视频扩散模型转化为实时交互式应用。其核心在于两层优化:一是实时调度与质量控制,包括SLO-aware批处理调度器(动态调整批大小以满足截止期限)、自适应sink和RoPE刷新(防止长时序漂移)以及运动感知噪声调度器(根据运动幅度适应去噪路径);二是可扩展pipeline编排,通过并行去噪步骤和网络阶段,实现跨GPU的近线性加速。此外,系统还融入了DiT块调度器、Stream-VAE和异步通信重叠等轻量优化,确保长时序流媒体的高利用率和稳定性。
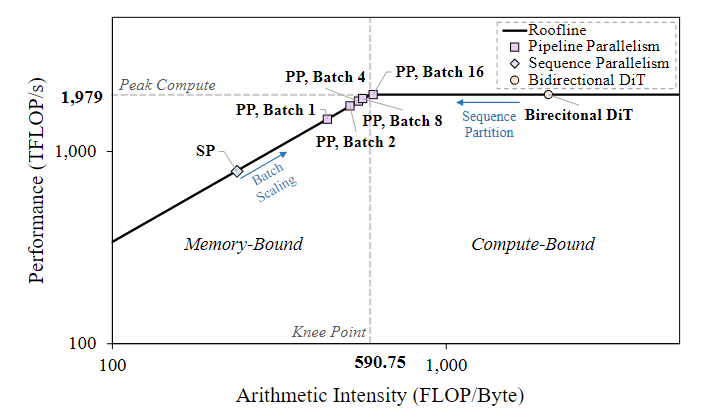
SLO感知的批处理调度器 (SLO-aware batching scheduler):为了在满足SLO的同时最大化GPU利用率,调度器根据目标帧率和当前硬件负载,动态调整批大小。调度器通过调整,使系统的工作点逼近硬件屋顶线模型(roofline model)的“膝点”,从而实现吞吐量最大化。
自适应sink与RoPE刷新 (Adaptive sink and RoPE refresh):为应对漂移,系统根据新块嵌入与旧sink集的余弦相似度来决定是否更新sink token。同时,当帧索引超过预设阈值时,周期性地重置RoPE相位,以消除累积的位置误差。
运动感知的噪声调度器 (Motion-aware noise scheduler):通过计算连续潜在帧之间的L2范数来估计运动强度,然后对归一化后的运动强度使用指数移动平均(EMA)来平滑地更新当前帧的噪声率,这使得高运动区域的去噪更保守,低运动区域的去噪更精细。
可扩展的pipeline编排 (Scalable pipeline orchestration):将DiT模块跨GPU进行划分,每个GPU作为一个微步(micro-step)处理其输入,并在一个环形结构中将结果传递给下一个GPU。这允许多个阶段并发执行,实现近线性的吞吐量加速。
系统级协同设计:还包括动态DiT块调度器(根据实时耗时动态重分配模块以平衡负载)、Stream-VAE(为流式处理优化的低延迟VAE变体)和异步通信重叠(使用独立的CUDA流隐藏GPU间通信延迟)。
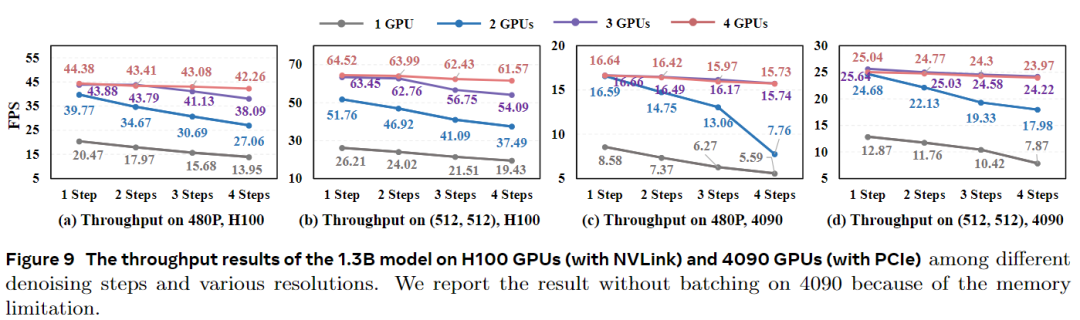
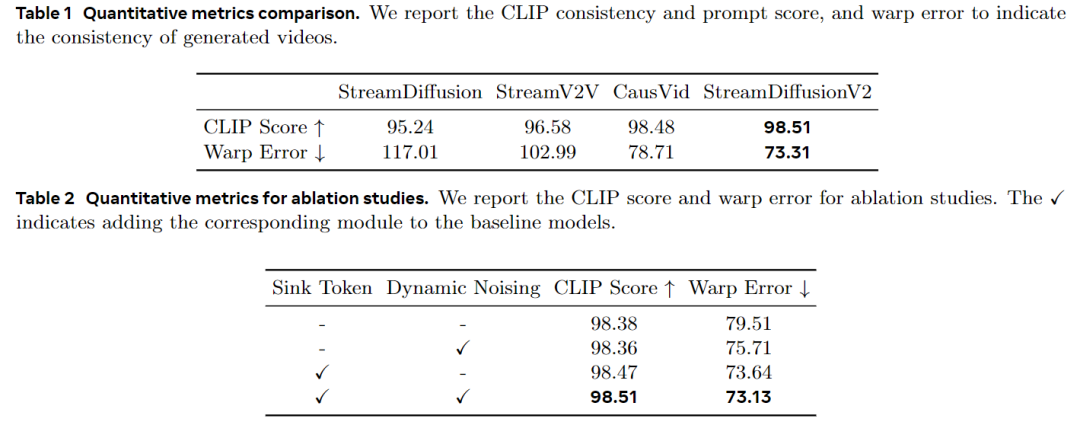
StreamDiffusionV2在无需TensorRT或量化的情况下,实现了0.5秒内首帧渲染,并在4个H100 GPU上以14B参数模型达到58.28 FPS,以1.3B参数模型达到64.52 FPS。即使增加去噪步骤以提升质量,仍保持31.62 FPS(14B)和61.57 FPS(1.3B)。系统在不同分辨率、去噪步数和GPU规模下表现出色,支持从低延迟到高品质的灵活权衡,并在CLIP分数(98.51)和Warp Error(73.31)等指标上超越基线,显著改善长时序一致性和运动处理能力。
StreamDiffusionV2,这是一个无需训练的流式系统,它同时实现了实时的效率和长时序的视觉稳定性。从高层次来看,本工作的设计基于两个关键的优化层面:
(1)实时调度与质量控制,它协同整合了服务等级目标(SLO)感知的批处理、自适应的sink与RoPE刷新、以及运动感知的噪声调度,以满足每帧的截止期限,同时维持长时序的时序连贯性和视觉保线)
,它通过跨去噪步骤和网络阶段进行并行化,以实现近线性的FPS扩展,且不违反延迟保证。此外,还探讨了数个轻量级的系统级优化,包括DiT块调度器、Stream-VAE和异步通信重叠,它们进一步增强了长时间运行的直播流的吞吐量和稳定性。
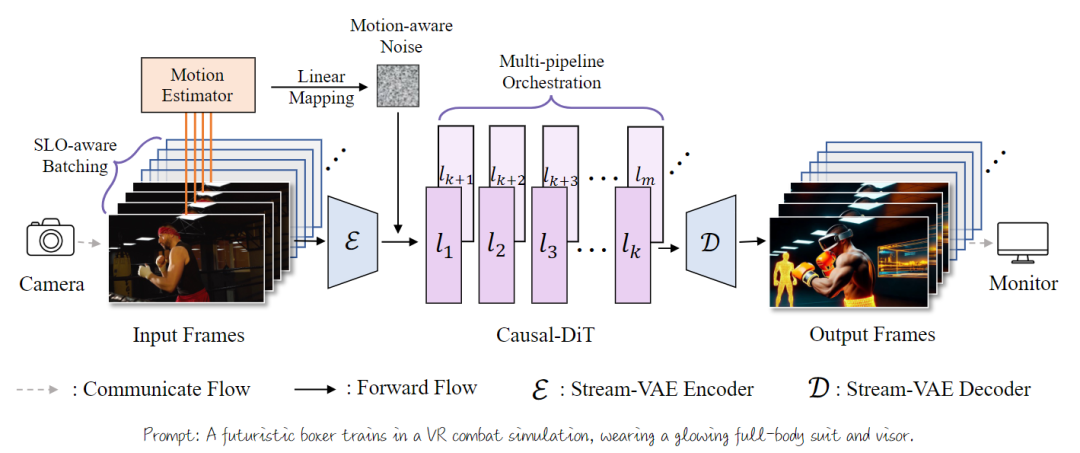
图 6 StreamDiffusionV2 的pipeline概览。(1) 效率。我们将 SLO 感知批处理调度器(控制输入大小)与pipeline协调配对,以平衡延迟和 FPS,确保每个帧在严格的服务限制条件下满足其截止日期和 TTFF。(2) 质量。我们部署了运动感知噪声控制器,以减轻高速撕裂,并将自适应汇令牌与 RoPE 刷新相结合,以提供高质量的用户交互和数小时级的流媒体稳定性。
如图6所示,StreamDiffusionV2通过三个关键组件实现实时视频生成:
,它动态调整流批次的大小,以满足每帧的截止期限,同时最大化GPU的利用率;(2)一个
,它根据运动的幅度来调整去噪轨迹,确保在多样的运动状态下都能保持清晰度和时序稳定性。
。为了在最大化GPU利用率的同时满足服务等级目标(SLO),本文提出了一个SLO感知的批处理调度器,用于动态调整批大小。给定一个目标帧率 ,系统每个迭代处理帧,其整体推理延迟取决于块大小T 和批大小B ,记为L(T,B)。为确保实时处理,乘积B.T不能超过已从输入流中收集的帧数。正如第3节所分析的,模型运行在内存受限的区域,推理延迟可以近似为:
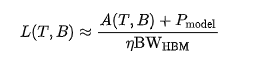
其中A((T,B)表示激活内存的占用,Pmodel代表模型参数的内存体积,而BWmm 是有效内存带宽,其利用因子为 ((01))。在使用FlashAttention时,激活项 A(T,B) 以 O(BT) 线性扩展,导致延迟 L(T,B)成比例增长。因此,实现的处理频率可以表示为 f= BT/L(T,B),它随着批大小的增大而增加,因为GPU的利用率得到了提升。当系统接近屋顶线)的膝点标志着从内存受限到计算受限的过渡调度器会自适应地收敛到一个最优的批大小 ,从而最大化吞吐效率。
。为了解决第3节中讨论的漂移问题,本文引入了一种自适应的sink token更新和RoPE刷新策略,它们共同维持了连续视频生成过程中的长时序稳定性。与之前的方法如Self-Forcing不同,StreamDiffusionV2根据不断演变的提示语义动态地更新sink tokens。令表示在块处的sink集。给定一个新的块嵌入,系统会计算相似度得分并刷新最不相似的sink:如果,则,否则,其中是一个相似度阈值。在实践中,本文发现应设置得较大,以确保持续与演变的文本对齐。为了防止因长时间序列中累积的RoPE偏移导致的位置漂移,本文周期性地在当前帧索引超过阈值时重置RoPE相位,即,若,则,否则。
。为了处理直播视频中多样的运动动态,本文提出了一个运动感知的噪声调度器,它根据近期帧的估计运动幅度,自适应地调节去噪的噪声率。
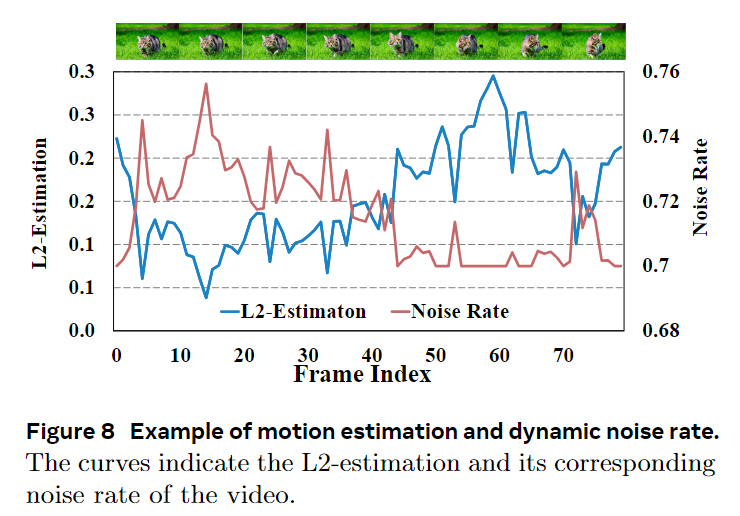
如图8所示,本文使用帧间差异度量来估计连续帧之间的运动幅度。给定连续的潜在帧,运动强度为:
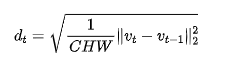
为了在一个较短的时间窗口(k帧)内稳定这个测量值,本文通过一个统计尺度因子将其归一化,并裁剪到[0, 1]区间内:
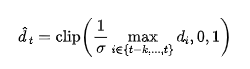
归一化后的决定了系统应该以多大的强度去噪当前的块。一个较高的(快速运动)对应一个更保守的去噪计划,而一个较低的(慢速或静态运动)则允许更强的细化以获得更锐利的细节。最后,本文使用指数移动平均(EMA)来平滑噪声率,以确保渐进的时序过渡:
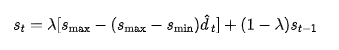
其中 01 控制更新率,而 Smax和Smin分别表示噪声率的上下界。
。为了在多GPU平台上提升系统吞吐量,本文提出了一种可扩展的pipeline编排方案用于并行推理。具体来说,DiT的模块被划分到不同的设备上。如图7所示,每个设备将其输入序列作为一个微步(micro-step)进行处理,并在一个环形结构内将结果传输到下一个阶段。这使得模型的连续阶段能够以pipeline并行的方式并发运行,从而在DiT的吞吐量上实现近线性的加速。
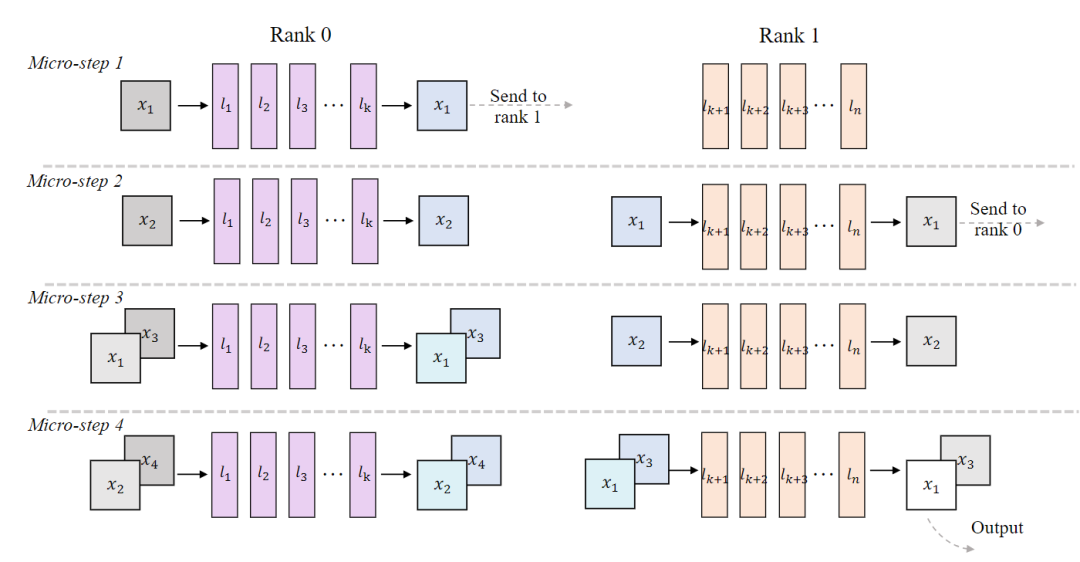
图 7 我们的pipeline-并行流-批处理架构的详细设计。DiT 模块分布在多个设备上以实现pipeline并行,而 Stream-Batch 策略则应用于每个阶段。不同颜色表示不同的潜流,说明了通信结构,深度表示相应的噪音水平。本文实现保证了在推理过程中的每个微步骤都能生成干净的潜变量。
值得注意的是,pipeline并行推理增加了阶段间的通信,这与激活流量一起,使得工作负载保持在内存受限状态。为了应对这一点并仍然满足实时约束,本文将SLO感知的批处理机制扩展到了多pipeline设置,并将其与批-去噪策略相结合。具体地,本文在每个微步(图7)都会产生一个精细去噪的输出,同时将n个去噪步骤视为一个有效的批次乘数,从而得到一个精炼的延迟模型。调度器会根据观察到的端到端延迟持续调整B,以使每个流的速率满足,而聚合的吞吐量则逼近带宽的屋顶线。
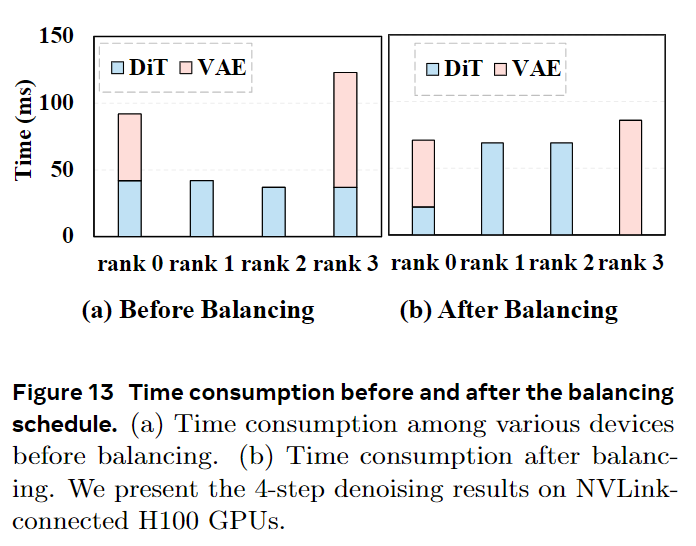
。静态分区常常会产生不均衡的工作负载,因为第一个和最后一个排名除了处理DiT块外,还要处理VAE的编码和解码,如图13(a)所示。这种不平衡会导致pipeline停顿和利用率降低。本文引入了一个轻量级的、在推理时运行的DiT块调度器,它根据测量的执行时间动态地在设备之间重新分配模块。该调度器会搜索一个最优的分区方案,以最小化每个阶段的延迟,如图13(b)所示,从而显著减少了整体的pipeline气泡。
。StreamDiffusionV2集成了一个为流式推理设计的低延迟Video-VAE变体。Stream-VAE不是编码长序列,而是处理短的视频块(例如4帧),并在每个3D卷积内部缓存中间特征,以维持时序的连贯性。
。为了进一步减少同步停顿,每个GPU都维护两个CUDA流:一个计算流和一个通信流。GPU间的传输是异步执行的,与本地计算重叠以隐藏通信延迟。这种双流设计使每个设备的计算节奏与其通信带宽保持一致,有效地缓解了残余的气泡,并在多GPUpipeline中保持了高利用率。
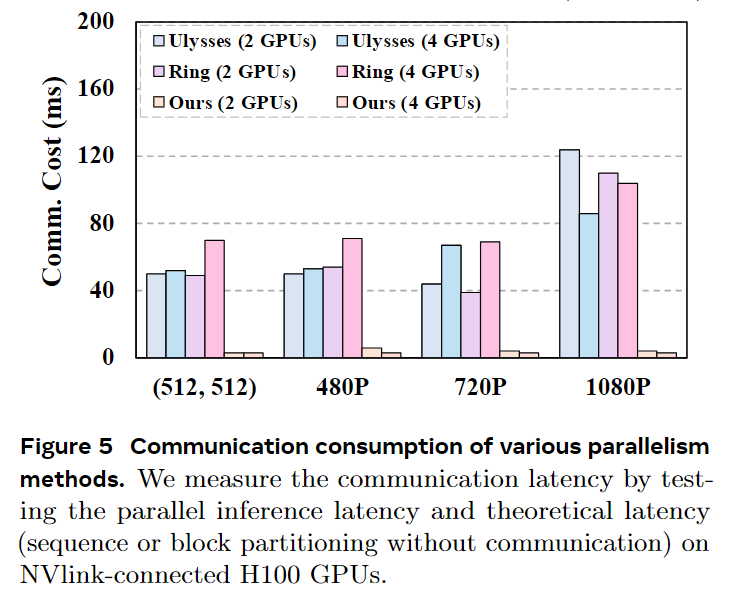
,本系统在CLIP分数(98.51)和Warp Error(73.31)上领先基线,视觉比较显示更好的一致性和运动处理。消融研究确认sink token和运动感知噪声控制器提升时序对齐。分析进一步验证动态DiT块调度器平衡负载,pipeline编排在通信和性能绑定上优于序列并行,Stream Batch显著提高吞吐量,尤其在多步骤下。
,弥合了离线视频扩散与受实时SLO约束的直播流媒体之间的差距。本免训练系统将SLO-aware批处理/块调度器与sink-token引导的滚动KV缓存、运动感知噪声控制器以及pipeline编排相结合,后者通过并行去噪步骤和模型层实现近线性FPS扩展,而不违反延迟要求。它在异构GPU上运行,支持灵活步骤计数,实现0.5 s TTFF,并在4×H100上达到58.28 FPS(14B)/ 64.52 FPS(1.3B),即使步骤增加也能维持高FPS。这些结果使最先进的生成式直播流媒体对单个创作者和企业平台都变得实用。参考文献
